Linear regression¶
This section will introduce linear regression, least squares fitting, and the relationship to probabilistic modelling and maximum likelihood estimation. Let’s start by considering a toy dataset (shown below) consisting of \(N=10\) scalar input and output pairs \(\{ x_{n}, y_{n} \}_{n=1}^N\). Our goal will be to make predictions at new input locations \(x^\star\).
# Load some prepared data
x_lin = np.load('data/reg_lin_x.npy')
y_lin = np.load('data/reg_lin_y.npy')
# Plot data
plt.figure(figsize=(8, 3))
plt.scatter(x_lin, y_lin, marker = 'x', color = 'red')
# Format plot
plt.title("A simple dataset", fontsize=24)
plt.xlabel("$x$", fontsize=18)
plt.ylabel("$y$", fontsize=18)
plt.xlim((-0.1, 1))
plt.ylim((0, 1.5))
plt.xticks(np.linspace(0., 1.0, 5), fontsize=14)
plt.yticks(np.linspace(0., 1.5, 4), fontsize=14)
plt.show()

A simple and popular approach to regression is fit a linear function to the data and use this to make predictions at new input locations. Denoting the slope of the linear function \(w_1\) and intercept \(w_0\), we have
Least Squares Fitting¶
The task is now to estimate the parameters \(w_0\) and \(w_1\) from the data. A straight line clearly can’t pass precisely through all of the datapoints because they aren’t collinear, but it is clear that some parameter choices will result in straight lines that go closer to data than others. A popular measure for the goodness of fit is the sum of square distances between each data point and \(f(x_n)\),
where equality with 0 holds only if \(~y_n = w_1x_n + w_0\) for every \(n\). By this measure, the optimal fit is the fit which minimises \(C_2\). This cost function, although intuitive, lacks justification. We will return to this issue at the end of this section.
The following animation encapsulates the proposed approach problem. In the left plot, we visualise lines corresponding to different settings of the parameters \((w_0, w_1)\) in data space \((x,y)\). The distances between the observed data and the fit are shown by grey dashes. The sum of the squares of these distances is \(C_2\). The right plot shows contours of the cost \(C_2\) in parameter space with blue indicating the cost is low and red high. The black cross shows the parameters of the line displayed on the left. When the cross moves horizontally in parameter space the intercept of the line changes and when the cross moves vertically the slope changes.
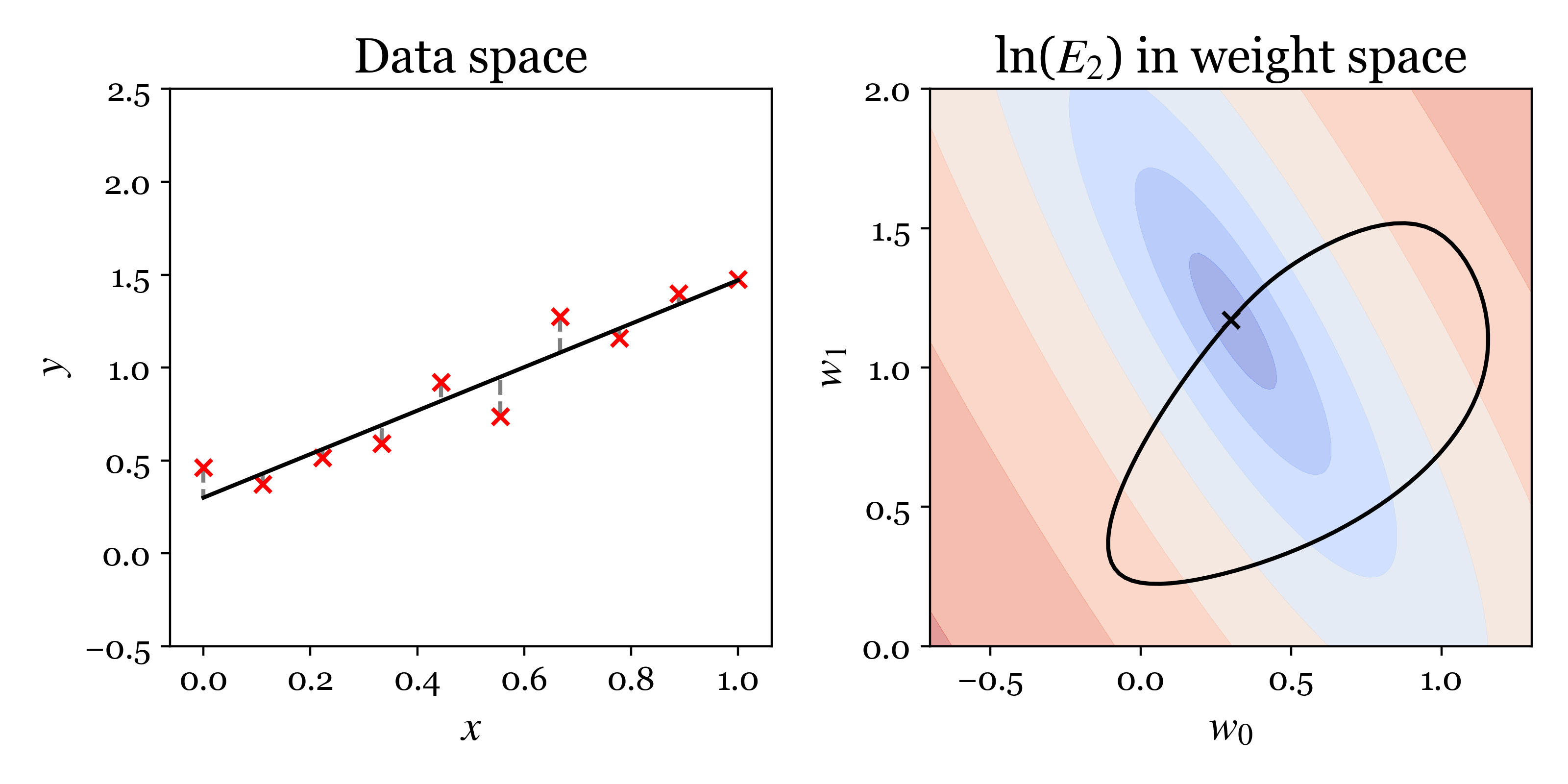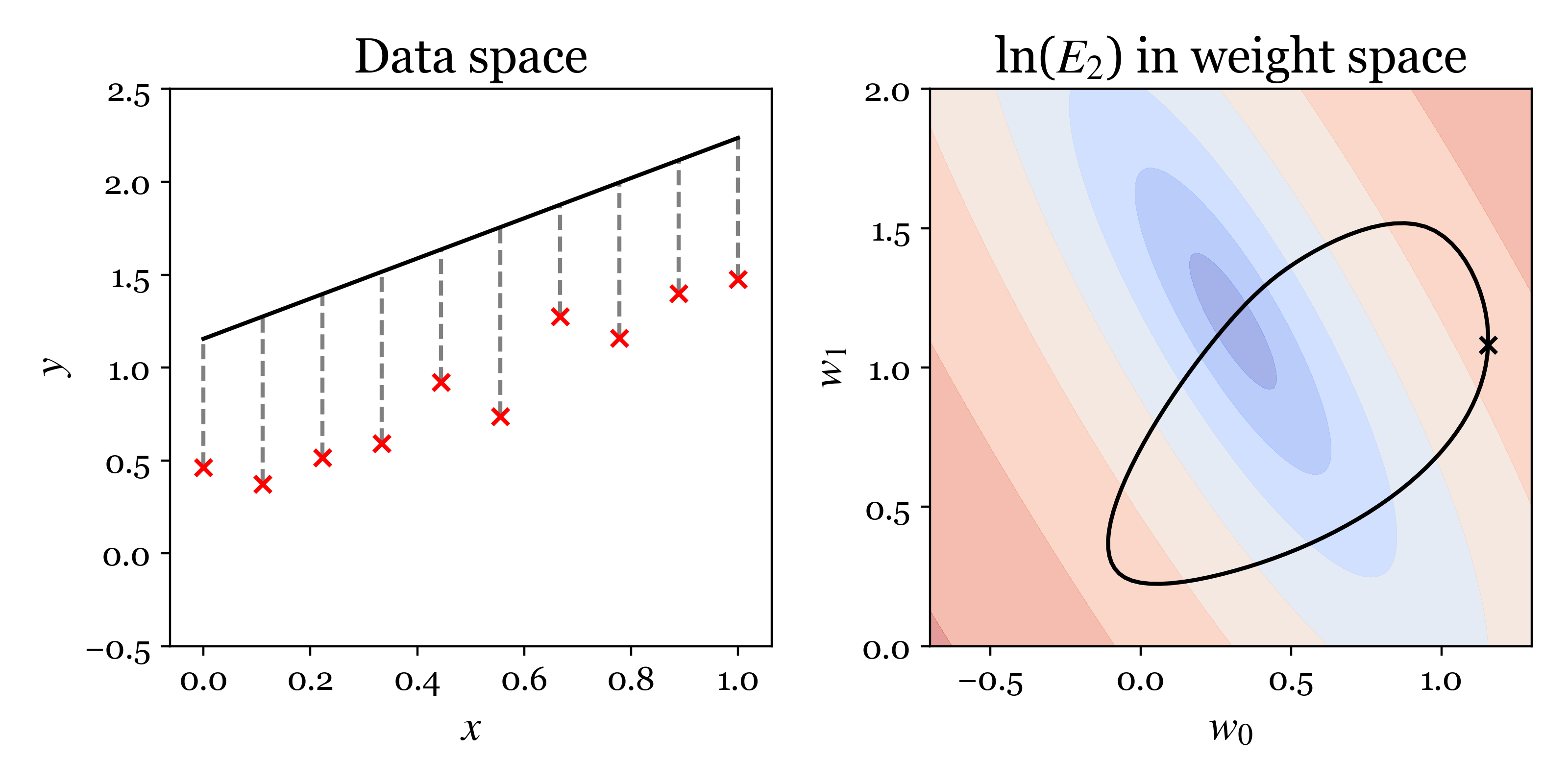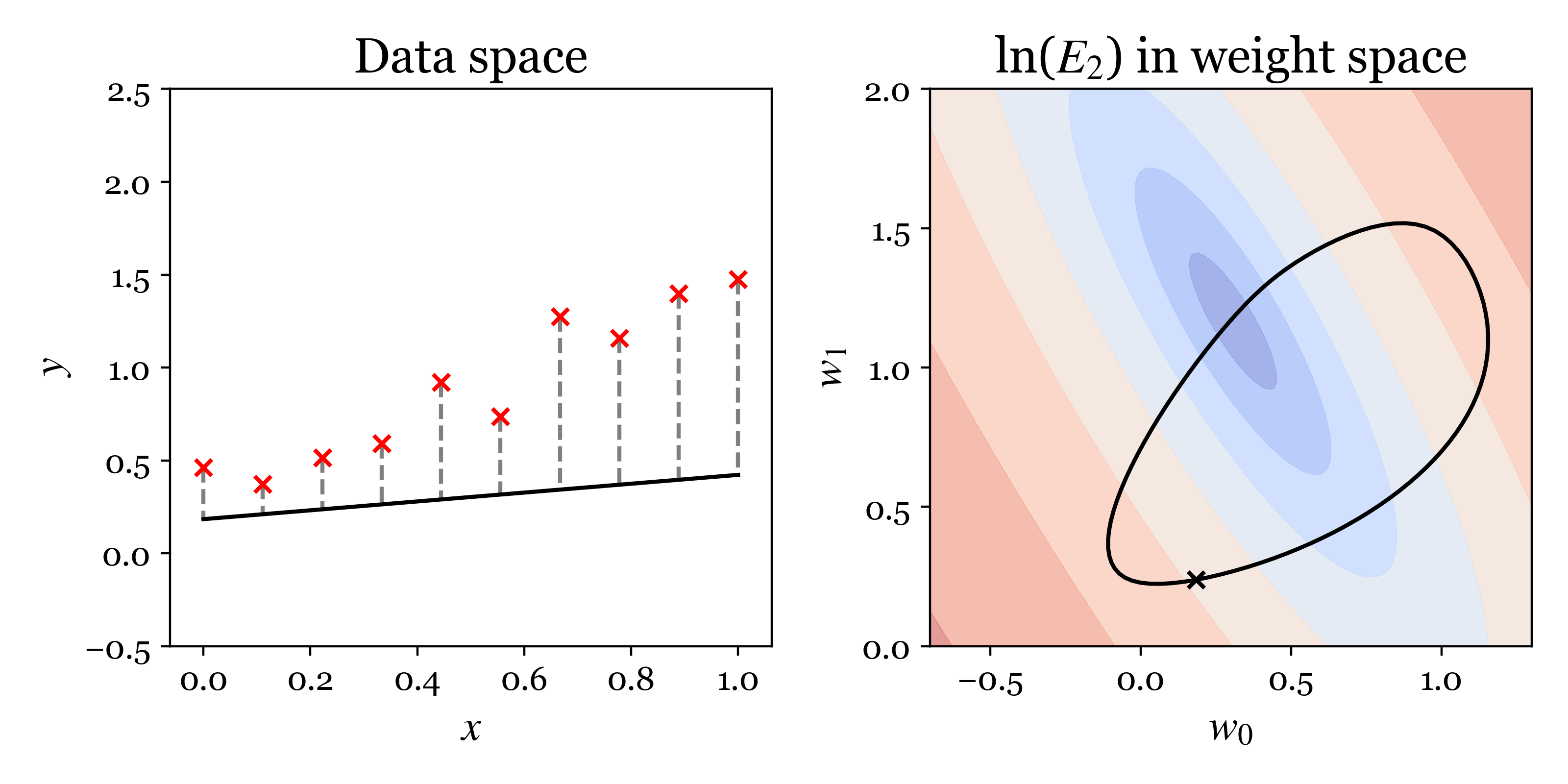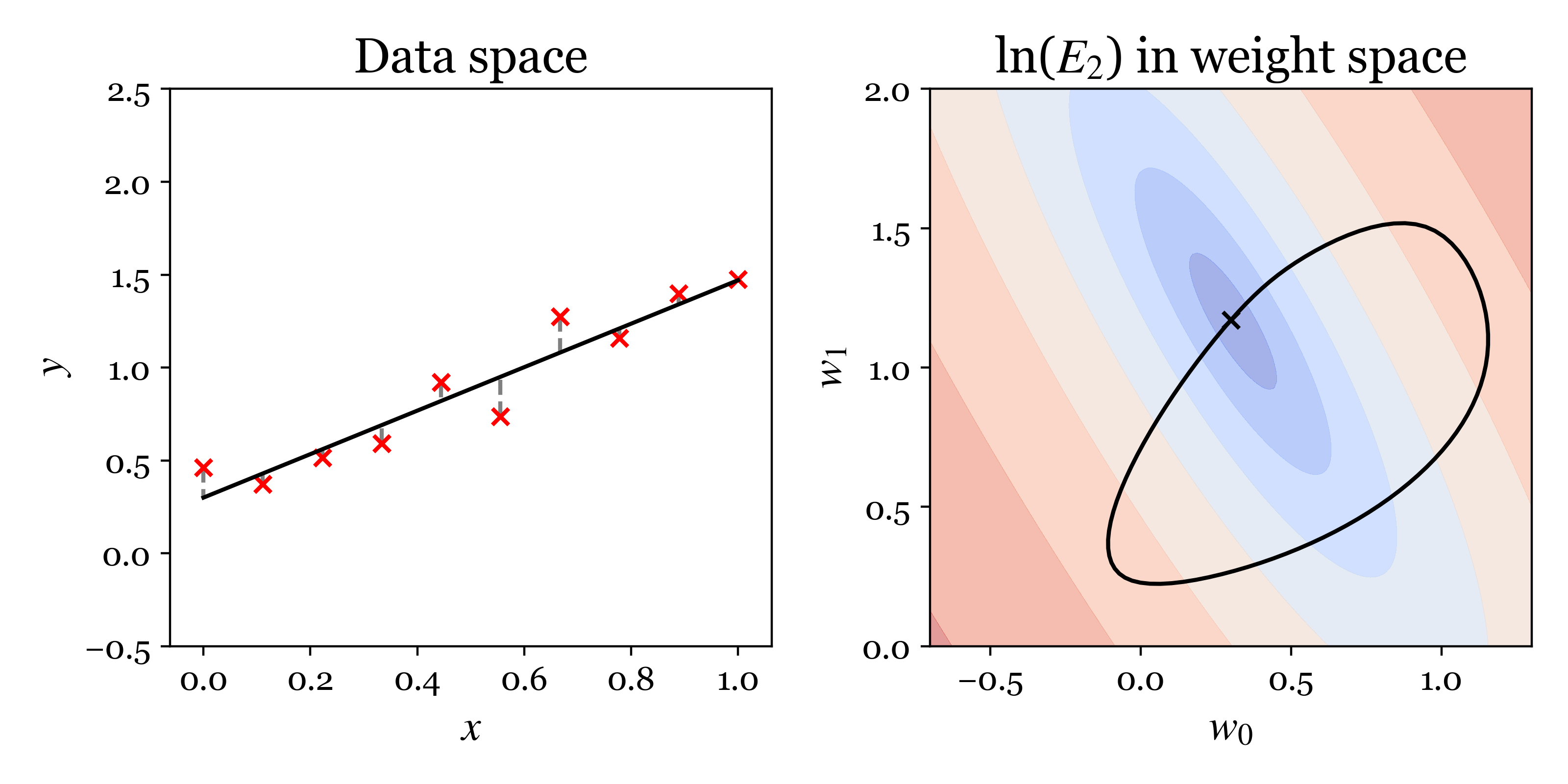
Analytic solution¶
Our goal is to find the parameters \((w_0, w_1)\) which minimise \(C_2\). Because the cost is a quadratic function of the parameters, this minimisation has an analytic solution. In order to derive that solution, we will first write the cost in a more compact and general form and second use differentiation to solve for the minimum.
Step 1: writing \(C_2\) in a more convenient form
The cost can be written in terms of a vector \(\mathbf{w}\) containing the model parameters, a vector \(\mathbf{y}\) that contains the training outputs, and a matrix \(X\) which contains the inputs augmented with a column of ones.
Details: Rewriting the cost more conveniently
Step 2: using differentiation to solve for the minimum.
Letting the derivative of a quantity \(f\) with respect to a vector \(\mathbf{v}\) to have have elements
we differentiate \(C_2\), set to zero, and obtain the closed form solution:
Details: Vector derivatives
We can write
As promised, when the matrix \(\mathbf{X}^\top\mathbf{X}\) is invertible, we have a closed form solution for \(\mathbf{w}\) which extremizes \(C_2\). You can convince yourself this is a minimum either by taking a second derivative or by considering the quadratic form of \(C_2\) and what happens in the limit of large \(\mathbf{w}\).
Further details and reading
In the expression for the least squares solution for the weights
the matrix \(\big( \mathbf{X}^\top\mathbf{X}\big)^{-1}\mathbf{X}^\top\) is a generalization of the inverse of a matrix for non-square matrices, called the Moore-Penrose pseudoinverse having the property
Note that when \(\mathbf{X}^\top\mathbf{X}\) is not invertible there is an infinity of solutions to the least squares problem. This occurs when the number of unique datapoints \(N'\) is smaller than the number of parameters we are fitting. For example, if we have a single datapoint, there are many ways of constructing a straight line that passes through the point.
More generally, when the inputs are \(D\) dimensional or when we’re fitting non-linear models with \(D\) basis functions the least squares solution is not unique when \(N'<D\). This is one of the motivations for approaches considered later that regularise the least squares solution and return unique solutions even when \(N'<D\).
Implementation¶
Below is an implementation of the least squares solution for finding the coefficients which minimise \(C_2\).
# Create a vector of ones with the same shape as x
ones = np.ones_like(x_lin)
# Stack ones and x's to get the X matrix
X = np.stack([ones, x_lin], axis = 1)
# Compute the optimal w using the Moore-Penrose pseudoinverse
w = np.linalg.solve((X.T).dot(X), (X.T).dot(y_lin))
# The above line is equivalent to the following:
#
# w = np.linalg.inv((X.T).dot(X)).dot(X.T).dot(y_lin)
#
# Unlike np.linalg.inv, the method np.linalg.solve avoids explicitly computing
# the matrix inverse, which can be numerically unstable. Instead it uses a linear
# solver, which is more stable. In general, if you don't explicitly need
# a matrix inverse, you should avoid computing it.
# 100 points equispaced between 0 and 1
x_pred = np.linspace(0, 1, 100)
# Evaluate the linear trendline at the points above
y_pred = (w[1] * x_pred) + w[0]
# Plot data
plt.figure(figsize=(8, 3))
plt.scatter(x_lin, y_lin, marker = 'x', color = 'red')
plt.plot(x_pred, y_pred, color = 'black')
# Format plot
plt.title(r"Linear fit (minimising $C_2$)", fontsize=24)
plt.xlabel("$x$", fontsize=18)
plt.ylabel("$y$", fontsize=18)
plt.xlim((-0.1, 1))
plt.ylim((0, 1.5))
plt.xticks(np.linspace(0., 1.0, 5), fontsize=14)
plt.yticks(np.linspace(0., 1.5, 4), fontsize=14)
plt.show()

Critique of the Least Squares fitting approach
Is the least squares procedure a sensible way to fit a linear model and return predictions?
One weakness in the rationale for the approach outlined above is that the cost function was drawn out of a hat. For example, instead of minimising the squared error, why not use an alternative cost in the family
From a computational perspective, minimising \(C_2\) is arguably a sensible choice as it yields a closed-form solution for the parameters (other choices do not), but it is not immediately clear if it is a statistically superior approach. However, in the next section we will show that minimising \(C_2\) is equivalent to a probabilistic approach that finds the parameters that are most likely, given the data, under the assumption of Gaussian observation noise.
Another weakness in the least squares approach is that it does not return uncertainty estimates in either the parameter estimates or the predictions. Framing the estimation as a probabilistic inference problem will later enable us to apply full blown probabilistic inference which does return uncertainties.
Maximum likelihood fitting¶
The least squares approach assumed that the function underlying the data was a straight line, but it did not explicitly specify how the observed data relates to this line. One simple assumption is that they are produced by adding independent and identically distributed Gaussian noise with zero mean and variance \(\sigma_{y}^2\),
\[y_n = w_0 + w_1 x_n + \epsilon_n,~\text{where}~ \epsilon_n \sim \mathcal{N}(0, \sigma_{y}^2).\]
This expression describes how to sample the outputs given the inputs and the model parameters, by computing the value the linear function takes at \(x_n\) and adding Gaussian noise. We can write down an equivalent expression for the probability density of the outputs \(\mathbf{y}\) given the inputs and model parameters (\(\mathbf{X}, \mathbf{w}, \sigma_y^2\)),
\[p(\mathbf{y}\mid\mathbf{X}, \mathbf{w}, \sigma_y^2) = \frac{1}{(2\pi \sigma_y^2)^{N/2}}\text{exp}\big(-\frac{1}{2\sigma_y^2}(\mathbf{y} - \mathbf{X}\mathbf{w})^\top (\mathbf{y} - \mathbf{X}\mathbf{w})\big)\]
This function is also known as the likelihood of the parameters and it can be used for fitting. The setting of the parameters that makes the observed data most probable is called the maximum likelihood estimate.
One way to find the parameters \(\mathbf{w}\) that maximise the likelihood is by directly taking derivatives of \(p(\mathbf{y}\mid\mathbf{X}, \mathbf{w}, \sigma_y^2)\). However, we can make our lives easier by maximising the log of the likelihood. This is equivalent since the logarithm is a monotonically increasing function (that is \(\log(x_1) > \log(x_2)\) if and only if \(x_1 > x_2\)), and the location of maxima and minima are unchanged by applying a monotonically increasing function. It is often simpler to handle logarithms of probabilistic quantities since:
probabilities often decompose into products which become sums once the logarithm is taken; and
many widely used probability distributions often involve the exponential function which simplifies after taking the log (the Gaussian being such a case).
Details: Monotonic transformations of functions
Consider a quantity \(\mathcal{Q}(x)\) with a (local or global) maximum at \(x^*\), and a monotonic function \(f\). Now consider \(Q\) in a neighbourhood around \(x^*\). Denoting a point in this neighbourhood as \(x^*+\delta\) we can restrict the size of neighbourhood by limiting the magnitude of the perturbation \(|\delta| < \epsilon\). For sufficiently small \(\epsilon\) due to \(x^*\) being a maximum, \(Q(x^*)>Q(x^*+\delta)\).
Now, we can apply the function \(f\) to both sides of this inequality and use the fact that it is monotonic to give
This demonstrates that \(x^*\) is also a (local/global) maximum of \(f(Q(x))\).
In this model the log-likelihood is
\[\mathcal{L}(\mathbf{w}) = \text{log}~ p(\mathbf{y}\mid\mathbf{X}, \mathbf{w}, \sigma_y^2) = -\frac{N}{2}\log(2\pi \sigma_y^2) -\frac{1}{2\sigma_y^2}(\mathbf{y} - \mathbf{X}\mathbf{w})^\top (\mathbf{y} - \mathbf{X}\mathbf{w})\]
maximising this quantity is equivalent to minimising the negative log-likelihood
\[-\mathcal{L}(\mathbf{w}) = \frac{N}{2}\log(2\pi \sigma_y^2) +\frac{1}{2\sigma_y^2}(\mathbf{y} - \mathbf{X}\mathbf{w})^\top (\mathbf{y} - \mathbf{X}\mathbf{w})\]
Notice that the term \(\frac{N}{2}\log(2\pi \sigma_y^2)\) is independent of \(\mathbf{w}\), so minimising the negative log-likelihood is equivalent to minimizing the least-squares error \(-\) exactly the same criterion we had before:
\[\boxed{\text{Least squares} \equiv \text{minimize}~ (\mathbf{y} - \mathbf{X}\mathbf{w})^\top (\mathbf{y} - \mathbf{X}\mathbf{w}) \Leftrightarrow \text{Maximum-likelihood}}\]
So the squared error assumption is equivalent to assuming that the observed data have been corrupted by Gaussian noise whose variance is fixed across the input space. One of the benefits of this new perpective (i.e. in terms of a probabilistic model and a specific inference scheme) is that the implicit assumptions are revealed, their suitability assessed, and modifications can be made. For example, the model could be generalised to include noise whose variance depends on the input location. Moreover, it might be important to infer the noise level \(\sigma_y\). The maximum likelihood approach paves the way to the Bayesian modelling approach where the task of infering the model weights retains uncertainty and incorporates prior knowledge. In subsequent chapters, we look at how to adapt our linear regression model to better deal with non-linear datasets that cannot be so accurately fit by a straight line.
Summary¶
Having covered linear regression, you should now understand:
Why the sum-of-squared-errors is used as a measure of fit.
How to manipulate the sum-of-square-errors cost into different forms.
How to derive the least squares estimate for the parameters of a linear model.
Why the least squares estimate is equivalent to the maximum likelihood estimate (under an i.i.d. Gaussian noise assumption).
Questions¶
- Probabilistic models for regression
A machine learner observes two separate regression datasets comprising scalar inputs and outputs \(\{ x_n, y_n \}_{n=1}^N\) shown below.

Suggest a suitable regression model, \(p(y_n|x_n)\) for the dataset A. Indicate sensible settings for the parameters in your proposed model where possible. Explain your modelling choices.
Suggest a suitable regression model, \(p(y_n|x_n)\) for the dataset B. Indicate sensible settings for the parameters in your proposed model where possible. Explain your modelling choices.
Answer
Part (a) A suitable regression model is a linear mode, with gradient \(\approx 5\) and an intercept at \((0, 0)\). The noise appears to be Gaussian but its standard deviation appears to grow with \(x\). Therefore an appropriate model including the noise would be
\[\begin{align} y_n(x) = 5x + \sigma(x) + \epsilon_n, \epsilon_n \sim \mathcal{N}(0, 1), \end{align}\]where \(\sigma(x) = |x|\). Note that there are several reasonable choices that could be made to model this data here.
Part (b) A suitable model here would be a sinusoidal trend, with period of aobut \(25\) time steps. Since there are outliers present, an appropriate noise model would be some heavy tailed model, such as a Student-t distribution:
\[\begin{align} y_n(x) = 2 + \sin \left(\frac{2\pi}{25}x\right) + \epsilon_n, \epsilon_n \sim \text{Student-t}. \end{align}\]Note that the choice of using a Student-t distribution here is perhaps hard to guess, but you should be able to identify that outliers are present and that a Gaussian noise model may not be the most appropriate choice here.
- Maximum-likelihood learning for a simple regression model
Consider a regression problem where the data comprise \(N\) scalar inputs and outputs, \(\mathcal{D} = \{ (x_1, y_1), ..., (x_N,y_N)\}\), and the goal is to predict \(y\) from \(x\).
Assume a very simple linear model, \(y_n = a x_n + \epsilon_n\), where the noise \(\epsilon_n\) is iid Gaussian with zero mean and variance 1.
Provide an expression for the log-likelihood of the parameter \(a\).
Compute the maximum likelihood estimate for \(a\).
Answer
Part (a) The likelihood for this model is
\[\begin{align} p(\{y_n\}_{n=1}^N | \{x_n\}_{n=1}^N, a) = \prod_{n=1}^N p(y_n, z_n | x_n, a). \end{align}\]Therefore the log-likelihood is
\[\begin{split}\begin{align} \log p(\{y_n\}_{n=1}^N | \{x_n\}_{n=1}^N, a) &= \sum_{n=1}^N \log p(y_n, z_n | x_n, a) \\ &= \sum_{n=1}^N \left[ -\frac{1}{2}\log 2\pi - \frac{1}{2} (y_n - ax_n)^2 \right] \\ &= -\frac{N}{2} \log 2\pi -\frac{1}{2} \sum_{n=1}^N \left[ (y_n - ax_n)^2 \right] = \mathcal{L}(a). \end{align}\end{split}\]Part (b) To find the maximum-likelihood estimate, we take a derivative of the log-likelihood with respect to \(a\) and equate this to \(0\), to obtain
\[\begin{align} \frac{d \mathcal{L}(a)}{da} &= - \sum_{n=1}^N \left[ x_n (y_n - ax_n) \right] = 0 \implies a = \frac{\sum_{n=1}^N x_n y_n}{\sum_{n=1}^N x_n^2} \end{align}\]
- Maximum-likelihood learning for multi-output regression
A data-scientist has collected a regression dataset comprising \(N\) scalar inputs (\(\{x_n\}_{n=1}^N\)) and \(N\) scalar outputs (\(\{y_n\}_{n=1}^N\)). Their goal is to predict \(y\) from \(x\) and they have assumed a very simple linear model, \(y_n = a x_n + \epsilon_n\).
The data-scientist also has access to a second set of outputs (\(\{z_n\}_{n=1}^N\)) that are well described by the model \(z_n = x_n + \epsilon'_n\).
The noise variables \(\epsilon_n\) and \(\epsilon'_n\) are known to be iid zero mean correlated Gaussian variables
\[\begin{split}\begin{align} p\left( \left[ \begin{array}{c} \epsilon_n\\ \epsilon'_n \end{array} \right ] \right) = \mathcal{N}\left( \left[ \begin{array}{c} \epsilon_n\\ \epsilon'_n \end{array} \right ]; \mathbf{0}, \Sigma \right) \;\; \text{where} \;\; \; \Sigma^{-1} = \left[ \begin{array}{cc} 1 & 0.5 \\ 0.5 & 1 \end{array} \right ]. \nonumber \end{align}\end{split}\]Provide an expression for the log-likelihood of the parameter \(a\).
Compute the maximum likelihood estimate for \(a\).
Do the additional outputs \(\{z_n\}_{n=1}^N\) provide useful additional information for estimating \(a\)? Explain your reasoning.
The formula for the probability density of a multivariate Gaussian distribution of mean \(\mu\) and covariance \(\Sigma\) is given by
\[\begin{align} \mathcal{N}(\mathbf{x};\mu,\Sigma) = \frac{1}{\sqrt{\text{det}(2 \pi \Sigma)}} \exp\left(-\frac{1}{2} (\mathbf{x} - \mathbf{\mu})^{\top} \Sigma^{-1} (\mathbf{x} - \mathbf{\mu})\right). \nonumber \end{align}\]Answer
Part (a) We can write the likelihood as
\[\begin{align} \mathcal{L}(a) = \log p(\{y_n\}_{n=1}^N, \{z_n\}_{n=1}^N | \{x_n\}_{n=1}^N, a) = \sum_{n=1}^N \log p(y_n, z_n | x_n, a) \end{align}\]where the terms \(p(y_n, z_n | x_n, a)\) are given by
\[\begin{split}\begin{align} p(y_n, z_n | x_n, a) = \mathcal{N}\left( \begin{bmatrix} y_n \\ z_n \end{bmatrix}; \begin{bmatrix} a x_n \\ x_n \end{bmatrix}, \begin{bmatrix} 1 & \frac{1}{2} \\ \frac{1}{2} & 1 \end{bmatrix}^{-1} \right). \end{align}\end{split}\]Substituting one expression into the other, we obtain
\[\begin{split}\begin{align} \mathcal{L}(a) &= -\frac{N}{2} \log \text{ det} (2\pi \Sigma) - \frac{1}{2} \sum_{n = 1}^N \left(\begin{bmatrix} y_n \\ z_n \end{bmatrix} - \begin{bmatrix} a x_n \\ x_n \end{bmatrix} \right)^\top \begin{bmatrix} 1 & \frac{1}{2} \\ \frac{1}{2} & 1 \end{bmatrix} \left(\begin{bmatrix} y_n \\ z_n \end{bmatrix} - \begin{bmatrix} a x_n \\ x_n \end{bmatrix}\right) \\ &= -\frac{N}{2} \log \text{ det} (2\pi \Sigma) - \frac{1}{2} \sum_{n = 1}^N \left[ (y_n - a x_n)^2 + (y_n - a x_n)(z_n - x_n) + (z_n - x_n)^2 \right] \end{align}\end{split}\]Part (b) Taking the derivative of the likelihood with respect to the parameter \(a\) and equating it to \(0\)
\[\begin{split}\begin{align} \frac{d\mathcal{L}(a)}{da} &= \frac{1}{2} \sum_{n = 1}^N \underbrace{2x_n(y_n - a x_n)}_{\text{Contribution from observing } y_n} + \underbrace{x_n (z_n - x_n)}_{\text{Contribution from observing } z_n} \\ &= \sum_{n = 1}^N \left[ x_n y_n - a x_n^2 + x_n (z_n - x_n) \right] = 0 \end{align}\end{split}\]followed by rearranging, we obtain the maximum-likelihood estimate of \(a\)
\[\begin{align} a = \frac{\sum_{n = 1}^N \left[ x_n y_n + x_n (z_n - x_n) \right]}{\sum_{n = 1}^N x_n^2}. \end{align}\]Part (c) The additionnal outputs change the ML estimate of \(a\). This means that they must provide useful information about \(a\). They do this because the noise in \(z_n\) is correlated with the noise in \(y_n\) and so observing \(z_n\) reveals information about the noise \(\epsilon_n\) and allows more accureate identification of \(a\).